Recent advances in 3D feedforward reconstruction neural networks have achieved remarkable success in dense reconstruction from images without any camera parameters. Yet, equipping these models with robust semantic understanding remains an open problem. Here we introduce an approach that performs 3D reconstruction and 3D panoptic segmentation in a unified framework.
Pano3D builds on existing 3D reconstruction models and augments them with a set-based mask decoder. The approach is jointly trained with a geometric and semantic loss, which are shown to be mutually beneficial. More precisely, the features are initialized from the geometric information and then fine-tuned to capture jointly geometry and semantics. We demonstrate the generality of our approach by successfully applying our framework both to online and all-to-all attention reconstruction backbones.
Our method achieves state-of-the-art performance in 3D panoptic segmentation across ScanNet, ScanNet200, and ScanNet++ datasets. Ablation studies show that such joint training of a unified model equips 3D feedforward reconstruction neural networks with panoptic segmentation and yields mutually beneficial improvements.
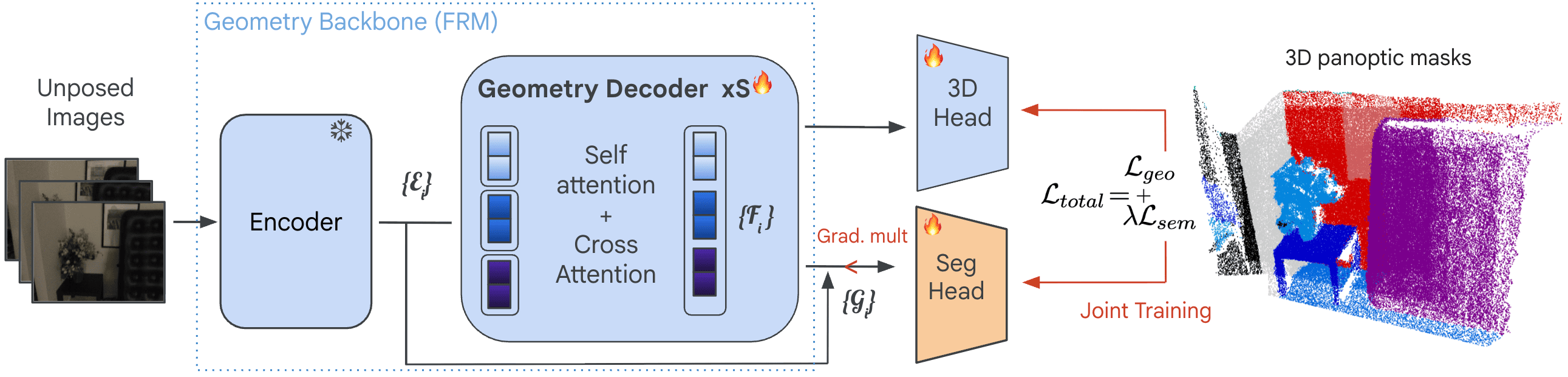
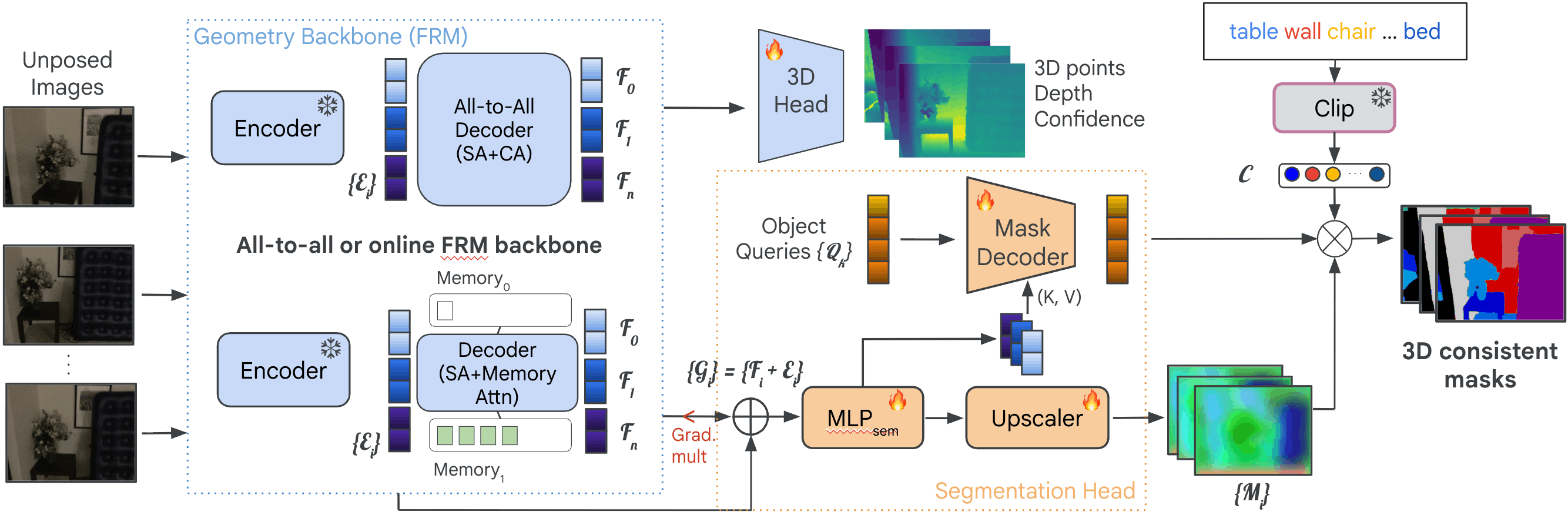
Pano3D eliminates heuristic clustering algorithms in favor of a natively differentiable, query-based panoptic head appended to a multi-view reconstruction backbone. By fusing features from the encoder with the final cross-view decoder features, we build representations that are both precise and scene-aware. Learnable object queries track unique 3D instances across the sequence.
Crucially, we fine-tune the multi-view decoder on both 3D reconstruction and panoptic segmentation jointly. This ensures that semantic gradients act as an implicit structural regularizer, grouping pixels into discrete entities without degrading geometric fidelity. We demonstrate improvement across two different geometry backbones, namely MUSt3R (Cabon et al., CVPR 2025) and Pi3 (Wang et al., ICLR 2026).
Confidence maps demonstrating how joint training modifies geometric understanding. The fine-tuned Pano3D model actively highlights ambiguous areas like glass windows and reinforces confidence on object centers despite shadows or reflections compared to the frozen baseline.



Coming soon...
@article{barberteguy2026pano3d,
author = {Barberteguy, Victor and Iscen, Ahmet and Caron, Mathilde and Fathi, Alireza and Varol, G{\"u}l and Schmid, Cordelia},
title = {{Pano3D}: Unified {3D} Reconstruction and Panoptic Segmentation},
journal = {arXiv preprint},
year = {2026},
}

